Современные информационные технологии/2. Вычислительная техника и программирование
Панкин А.В.
Открытое
акционерное общество «Научно-исследовательский институт «Аргон», Россия
Метод параллельной обработки данных
вычислительного устройства на основе ПЛИС и технологии система на кристалле
Сегодня развитие вычислительной техники
происходит по всем направлениям, в первую очередь благодаря развитию
микроэлектроники и за счет появления все новых и более сложных задач, которые
необходимо обрабатывать все с большей интенсивностью и надежностью. Поэтому
перед инженерами стоит непростая задача, в первую очередь за счет применения
современных электронных компонент, поддерживать тенденцию повышения
производительности и создавать новое поколение вычислительной техники. Активно
развиваемым направлением создания вычислительных устройств являются
системы-на-кристалле (СнК). В результате быстрого развития интегральных
технологий на одном кристалле становится возможным размещать целые системы (процессорную часть, память,
интерфейсные схемы и др.).
Встраиваемые в FPGA блоки
обработки данных позволяют полностью удовлетворить требованиям заказчика и
добиться масштабируемой производительности. По сути, FPGA являются платформами
общего назначения, на базе которых разработчики проектируют одно- или
многопроцессорные системы. Благодаря возможности FPGA интегрировать функцию
обработки данных с помощью встроенного аппаратного или программного
процессорного блока разработчики настраивают системы таким образом, чтобы
удовлетворить требованиям специализированных приложений. Возможности FPGA не
ограничиваются заранее определенной системной архитектурой — эти ИС
программируются и настраиваются. На самом деле, благодаря FPGA достигается
баланс между процессором, выполняющим команды и функции управления, и логикой
FPGA, осуществляющей обработку данных с высокой скоростью. Основные преимущества
систем на кристалле:
– возможность получения более высоких
технических показателей (производительность, энергопотребление, массогабаритные
характеристики);
– более низкая стоимость при крупносерийном выпуске.
Вычислительные устройства, реализованные
по технологии СнК на базе FPGA,
представляют собой новый, достаточно специфический класс параллельных устройств
вычислительной техники. Специфика технологии реализации СнК заставляет заново
оценивать и пересматривать, дополнять сложившиеся методы и критерии
проектирования ВС для применения их к разработке специализированных
вычислительных устройств.
Структура вычислительного
устройства
На рисунке 1 представлена структурная схема типового специализированного вычислительного устройства, состоящего из нескольких модулей. В его задачи входят, прием входного сигнала по ГОСТ 18977, его обработка, например, передача по нескольким коммутируемым каналам, вывод информации на монитор, прием управляющей информации с пульта управления.
Для связи процессорного модуля с интерфейсными модулями, используется общая шина. Вычислительная машина состоит из трех основных элементов:
- блок питания;
- объединительная плата, с общей шиной;
- модули интерфейсов;
- процессорный модуль;
При реализации такой архитектуры в функции процессора
входят инициализация интерфейсных модулей, сбор и обработка данных с общей шины,
прием и обработка управляющей информации, и передача обработанной информации по
одному или нескольким основным каналам передачи данных. Для этого нередко
требуется достаточно мощный и быстродействующий
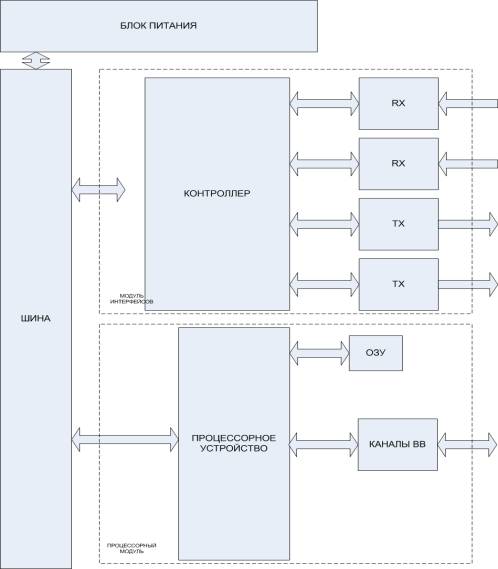
Рисунок 1 – Структурная схема типового вычислительного
устройства
процессор, поэтому для таких устройств необходимы громоздкие системы отвода тепла. Процессорный модуль полностью управляет всеми процессами вычислительной машины. Поэтому по мере увеличения количества интерфейсных модулей, возрастает вычислительная нагрузка на процессорный модуль.
Модуль интерфейсов реализует процесс обмена данными вычислительного устройства с внешними устройствами по последовательным каналам ГОСТ 18977, в настоящее время это самый распространенный способ обмена информацией на летательных аппаратах. Состоит из двух передатчиков, двух приемников последовательного сигнала, контроллера, обеспечивающего преобразование последовательного сигнала по ГОСТ 18977 в параллельный сигнал общей шины. Работа модуля интерфейсов полностью управляется процессорным модулем в соответствии с программой.
В последние годы наметилась устойчивая
тенденция использования новых архитектурных решений для повышения
производительности вычислительных устройств. Одним из наиболее распространенных
решений является использование программируемых логических интегральных схем
(ПЛИС) для выполнения вычислений. ПЛИС обладают большим вычислительным
потенциалом, который в полной мере может быть реализован для задач
вычислительного устройства. На рисунке 2 представлена структурная схема
вычислительного устройства выполненного по технологии СнК на ПЛИС FPGA.
Представленная структура отличается от
типового варианта реализации, наличием на интерфейсном модуле
высокоинтегрированной ПЛИС типа FPGA, включающую
в свою структуру встраиваемые микропроцессоры, оперативную память, а также
блоки обработки данных по ГОСТ 18977.
В качестве микропроцессорного ядра
используются синтезируемые процессорные ядра (Soft Processor Cores), которые представляют собой
СФ-Блоки, разработанные и оптимизированные в качестве процессорных ядер для
СнК, реализуемых на ПЛИС. Данные о характеристиках некоторых современных синтезируемых
процессорных ядер приведены в таблице 1.
Таблица
1 – Параметры синтезируемых процессорных СФ-Блоков
|
Процессорные СФ-блоки |
Разрядность |
Тактовая частота, МГц |
Производительность, DMIPS |
Число LUT |
|
PicoBlaze
(Xilinx) |
8 |
250 |
125 |
110 |
|
MicroBlaze
(Xilinx) |
32 |
200 |
166 |
1250 |
|
Nios II Economy (Altera) |
8 |
200 |
31 |
600 |
|
Nios II Standart (Altera) |
16 |
165 |
127 |
1300 |
|
Nios II Fast (Altera) |
32 |
185 |
218 |
1800 |
|
LEON3*
(Gaisler) |
32 |
150 |
150 |
3500 |
|
AMOEBA |
32 |
150 |
100 |
2000 |
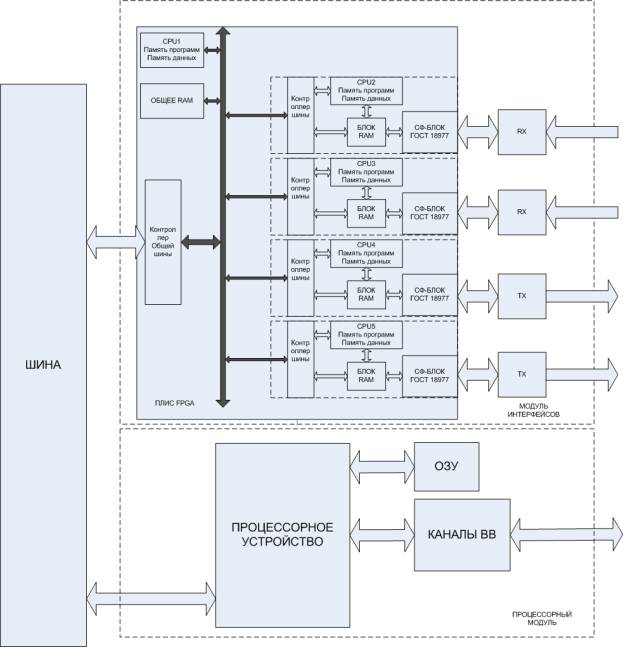
Рисунок 2 – Структурная схема вычислительного
устройства выполненного
по технологии СнК на ПЛИС FPGA
В данной реализации микропроцессоры CPU2 и CPU3 выполняют
основные задачи вычислительного устройства по первичной обработке сигналов по
ГОСТ 18977 и записи информации в ОЗУ. Микропроцессоры CPU4 и CPU5 отвечают за
передачу последовательного сигнала.
Таким образом, вычислительная нагрузка на процессорный модуль
существенно снижается. Его основным назначением становится мониторинг
работы интерфейсного модуля.
Микропроцессор CPU1 (основной процессор) организует связь между данными
последовательного сигнала и контроллером общей шины. Также, при наличии в блоке
вычислительного устройства нескольких модулей, микропроцессор CPU1 способен обращаться к ним на прямую, без
вмешательства в процесс процессорного модуля. Например, для коммутации сигнала
по другим каналам интерфейсных модулей. Блок общей оперативной памяти,
необходим процессору CPU1 для
временного хранения обрабатываемых данных всех четырех каналов связи. Каждый
канал имеет свое адресное пространство в блоке общей оперативной памяти.
Четыре СФ-блока приема и передачи
информации по ГОСТ 18977, реализованы в виде VHDL – описания, и
занимают всего 1% от ресурсов кристалла XILINX xc3s500e. Их функциями
является первичная обработка сигнала.
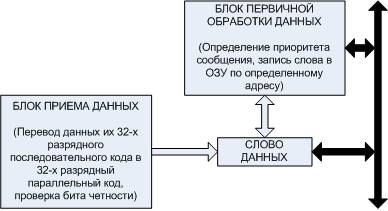
Рисунок 3 – Структурная схема СФ-Блока приема
информации по ГОСТ 18977
Входной, последовательный код, попадая в
блок приема данных преобразуется в параллельный 32-х разрядный код. Далее блок
первичной обработки данных анализирует сигнал и определяет его приоритет с
последующей записью в RAM в соответствии с приоритетом. Процессорный блок CPU2 (канальный процессор) считывает данные с RAM, и производит расчеты в соответствии с программой. По
необходимости, данные идут дальше в общий блок RAM для анализа и
последующей передаче обработанных данных процессорному модулю. Весь процесс
обработки данных длится от 40 нс до 400 нс.
В таблице 2 представлены характеристики
синтезированных СФ – Блоков обработки сигнала по ГОСТ 18977.
Таблица 2 – Параметры синтезируемых СФ-Блоков
приемника и передатчика последовательного интерфейса по ГОСТ 18977
|
СФ-блоки |
Тактовая частота, МГц |
Производительность,
DMIPS |
Число LUT |
|
RX ГОСТ18977 |
150 |
50 |
65 |
|
TX ГОСТ18977 |
150 |
50 |
58 |
СФ-Блок оперативной памяти реализован также,
как Soft core, и описан
на языке VHDL.
Таблица
3 – Параметры синтезируемого СФ-Блока ОЗУ
|
СФ-блоки |
Тактовая частота, МГц |
Производительность,
DMIPS |
Число LUT |
|
ОЗУ |
100 |
50 |
500 |
При
разработке данной структуры был использован важный принцип – распараллеливание
выполняемых задач с разделением системы на функциональные блоки. Каждый
канальный процессор обрабатывает информацию только своего канала. Таким
образом, при приеме сразу двух сигналов одновременно, ни один сигнал не
потеряется, как это возможно в случае с типовой реализацией. На аппаратной
платформе такую структуру зачастую невозможно реализовать, поскольку и
процессор, и контроллеры имеют ограниченный фиксированный набор интерфейсов.
Как правило, все периферийные контроллеры подключаются на одну и ту же шину
процессора, и, соответственно, обращаться к ним процессор может только
последовательно. Но главное – большинство контроллеров требуют внешнего
управления и не могут самостоятельно обмениваться данными или выполнять
какие-либо совместные действия.
Такая
структура, в которой наряду с основным мощным процессором параллельно работают
более простые микроконтроллеры и блоки управления периферийными устройствами и
контроллерами, позволяют существенно разгрузить основной процессор.
Весь набор
СФ-Блоков при интеграции в ПЛИС Xilinx xc3s500e занимает
около 55% ее внутренних ресурсов. Таким образом, существует значительный запас,
который можно использовать для усовершенствования алгоритмов работы или
расширения набора интерфейсов модуля.
Литература:
1. Немудров В., Мартин Г. Системы на кристалле.
Проектирование и развитие. — М.: Техносфера, 2004, с. 216.
2. Шагурин И., Шалтырев В., Волов А. «Большие» FPGA
как элементная база для реализации систем на кристалле//Электронные компоненты,
2006, №5, c.83—88.
3. Адамов Ю.Ф. Проектирование систем на кристалле.
c.2—48.
4. Шагурин И. Системы на кристалле. Особенности
реализации и перспективы применения. Время электроники, 2006.
5. Карпов С. Разработка систем на кристалле на базе
ПЛИС Actel. http//actel.ru