Современные информационные технологии/ Информационная безопасность
Дубчак О. В., Максімов Ю.О.
Національний авіаційний університет(НАУ), Україна
КРИТЕРІАЛЬНИЙ АНАЛІЗ МЕТОДІВ ОБРОБКИ ВИХІДНИХ
ДАНИХ У БІОМЕТРИЧНИХ СИСТЕМАХ
Вступ Звичайні методи ідентифікації особистості, в основі яких лежать різні
ідентифікаційні картки, ключі чи унікальні дані такі, як пароль і PIN, не є
надійними в необхідній на сьогодення мірі. Рівень захисту інформації потребує
більш ефективних, надійних та достовірних способів отримання даних про
користувача. Логічним кроком у напрямку підвищення надійності ідентифікації виявилися
спроби використання біометричних технологій для систем безпеки, наслідком чого
став стрімкий, якісно новий розвиток значної кількості технологічних рішень щодо
їх впровадження у системи.
Актуальність В теперішній час біометричні технології розробляються й удосконалюються, в
основному, за кордоном. У країнах
Європи, Північної Америки, Індонезії та Східної Азії діяльність приватних фірм,
урядових організацій та лабораторій з питань біометрії, ефективності їх
використання та впровадження узгоджується
та координується Біометричним
Консорціумом - BioAPI Consortium. Провідними виробниками біометричних систем є
Bio-lіnk Technologics, Bioscrypt, Precise Biometries, Neurotechnologiya. Digital Persona, Ethentica, Indentix,
Staflink, Veridicom тощо. Тому актуальним є створення та розробка вітчизняних стандартів
та методів реалізації пристроїв, заснованих на біометричних технологіях, не
тільки з метою ліквідації залежності від закордонних виробників, а й для
подальшого вдосконалення біометричних систем та забезпечення захисту інформації
на національному рівні.
Постановка завдання У всіх біометричних системах технологічно існують загальні підходи до
вирішення задачі ідентифікації та аутентифікації, але методи відрізняються
зручністю застосування і точністю результатів. Будь-яка біометрична система
захисту складається із поетапних способів опрацювання інформації:
- сканування об'єкту ідентифікації;
- отримання індивідуальної інформації за певною ознакою;
- створення та формування шаблону даних (оптимізація вихідних даних);
- порівняння поточного об’єкту із шаблоном у базі даних (БД).
Для аналізу найбільш технічно проблематичного аспекту біометричних
систем, а саме процесу порівняння отриманих вихідних даних з попередньо розташованими зразками
в заздалегідь сформованій базі даних, пропонуємо розгляд цього етапу в найуживаніших методах розпізнавання людини за
її біометричними ознаками та оцінювання даних методів за співвідношенням
показників швидкодії роботи системи та її точності й надійності.
Для
проведення порівняння необхідно вихідний потік даних, що надходять від
біометричних датчиків, класифікувати таким чином, що б кожний клас відповідав
одному з об'єктів дослідження, тобто в нашому випадку - одному із записів в БД
системи управління контролю доступу.
Із достатньої кількості існуючих методів віднесення об'єкта до певного класу на підставі
його ознак було обрано методи класифікації, найчастіше застосовувані в системах
контролю доступу за біометричними ознаками:
- „Дерево рішень”;
- „Прихована модель Маркова”;
- „Нейронна мережа”;
- „![]() -найближчих сусідів”;
-найближчих сусідів”;
- „Двоетапний класифікатор”;
- „Відхилення вибору”.
Метод класифікації „Дерево
рішень” Дерева прийняття рішень зазвичай використовуються для
вирішення задач класифікації даних або, інакше кажучи, для задачі апроксимації
заданої булевої функції. Цей спосіб побудови дерев використовує методи,
розроблені Л.Ейлером. За технологією, яка використовується для побудови дерев
рішень, існує набір значної кількості простих ознак. Кожна ознака окремо
забезпечує тільки деякі відомості для вирішення задачі класифікації. Однак
комбінація таких ознак може надати важливу інформацію, необхідну для прийняття
точного рішення про належність до відповідного класу. [1]
Метод класифікації „Прихована
модель Маркова” „Приховані моделі Маркова” (ПММ) -
форма стохастичного кінцевого стану автомата, придатного для розпізнавання,
наприклад, образів і мови. Ці моделі здатні класифікувати дані, засновані на
великій кількості ознак, число яких є змінним, і мають певні типи основної
структури (див.рис.1).
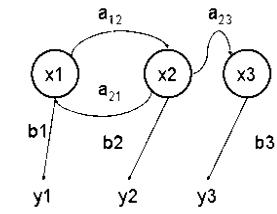
Рис.1. Приклад
діаграми переходів у ПММ: х- приховані стани; у –результати спостережень; а –
ймовірності переходів; b- ймовірність результату.
Наприклад, при проведенні ідентифікації за відбитком
пальця основна інформація для класифікації може бути виведена з синтаксичного
аналізу особливих точок, і може полягати в загальному вигляді виступів. ПММ здатна
статистично моделювати різні структури зразків за цілим відбитком, не
ґрунтуючись на отриманні особливих точок. Як правило, ПММ - одномірні
структури, які підходять для аналізу тимчасових даних. [4]
Метод класифікації „Нейронна
мережа” Відомо, що штучний нейрон, так само як і живий,
складається з: синапсів, що пов'язують входи нейрона з ядром; безпосередньо
ядра нейрона, яке здійснює обробку сигналів; аксона, який пов'язує даний нейрон з нейронами наступного шару.
Кожний синапс має вагу, яка визначає, наскільки відповідний вхід нейрона впливає
на його стан. На нейронний елемент надходить набір вихідних сигналів, що
представляє собою вихідні сигнали інших нейроподібних елементів (див.рис.2).
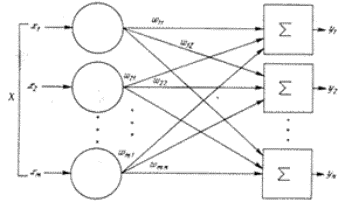
Рис.2. Схема надходження на нейронний елемент вихідних
сигналів
Кожний вихідний сигнал помножується на
відповідну вагу зв'язку - аналог ефективності синапсу. Вага зв'язку є скалярною
величиною, позитивною - для збуджуючих,
негативною - для гальмуючих
зв'язків. Коефіцієнти у зваженій сумі, зазвичай, називають синоптичними коефіцієнтами
або вагами. Саму ж зважену суму
називають потенціалом нейрона.
Зважені вагами зв'язків вихідні сигнали надходять на блок сумації, відповідний
тілу клітини, де здійснюється їх алгебраїчна сумація і визначається рівень
збудження нейроподібних елементів. Потім отримана сума порівнюється із заданою
пороговою величиною, слідом вступає в дію нелінійна функція активації
(див.рис.3).
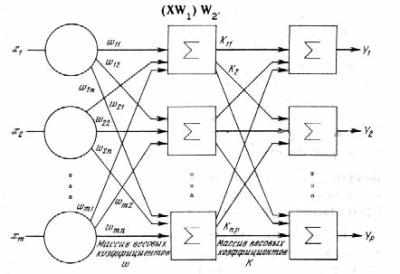
Рис.3. Схема
порівняння результуючої та порогової сум
У
системах контролю доступу часто використовують багатошарову нейронну мережу, тобто
з прямим розповсюдженням, застосовуючи в якості навчального алгоритму алгоритм
швидкого розповсюдження. [1, 5]
Метод класифікації „![]() -найближчих сусідів” Метод
полягає в наступному. Спочатку виявляють
-найближчих сусідів” Метод
полягає в наступному. Спочатку виявляють ![]() -найближчих сусідів для тестового зразка в просторі ознак. Тестовий
зразок належить до класу, який найбільш часто представлений серед його
найближчих сусідів. Два верхніх класи, які були знайдені за допомогою
класифікації за методом
-найближчих сусідів для тестового зразка в просторі ознак. Тестовий
зразок належить до класу, який найбільш часто представлений серед його
найближчих сусідів. Два верхніх класи, які були знайдені за допомогою
класифікації за методом ![]() -найближчих сусідів, повинні відповідати класам, які мають
найвищу і другу за величиною кількість серед найближчих елементів. Зазвичай
розглядаються 10 елементів, тобто
-найближчих сусідів, повинні відповідати класам, які мають
найвищу і другу за величиною кількість серед найближчих елементів. Зазвичай
розглядаються 10 елементів, тобто ![]() . Точність класифікації не завжди збільшується зі збільшенням
. Точність класифікації не завжди збільшується зі збільшенням
![]() . Тут виникає проблема класифікації, пов'язана з визначенням
оптимальної величини
. Тут виникає проблема класифікації, пов'язана з визначенням
оптимальної величини ![]() для обсягу
перевірочної вибірки кінцевого розміру.[2,3]
для обсягу
перевірочної вибірки кінцевого розміру.[2,3]
Метод класифікації „Двоетапний
класифікатор” Як окремий випадок можна розглядати „Двоетапний
класифікатор”, який є системою, що об'єднує методи класифікації „![]() -найближчих сусідів” і „Нейронна мережа”: класифікація за
методом „
-найближчих сусідів” і „Нейронна мережа”: класифікація за
методом „![]() -найближчих сусідів” використовується для виконання простої
класифікації, потім використовується
набір двокласових нейронних мереж для підвищення точності.
-найближчих сусідів” використовується для виконання простої
класифікації, потім використовується
набір двокласових нейронних мереж для підвищення точності.
Перший етап використовує метод „![]() -найближчих сусідів” при
-найближчих сусідів” при ![]() , щоб вибрати два найбільш вірогідних класи для поточного вихідного
зразка. Встановлено, що приблизно у 85.4% випадків клас з максимальною частотою
попадання в групу 4-найближчих сусідів – „правильний” клас, тобто такий,
що пройшов класифікацію, і в 12.6%
випадків - клас з другою за величиною
частотою, також – „правильний” клас. Іншими словами, застосування методу
класифікації „
, щоб вибрати два найбільш вірогідних класи для поточного вихідного
зразка. Встановлено, що приблизно у 85.4% випадків клас з максимальною частотою
попадання в групу 4-найближчих сусідів – „правильний” клас, тобто такий,
що пройшов класифікацію, і в 12.6%
випадків - клас з другою за величиною
частотою, також – „правильний” клас. Іншими словами, застосування методу
класифікації „![]() - найближчих сусідів” приводить до знаходження двох класів з
найбільшою частотою попадання в групу з точністю 98%. Цей результат не використовується
для точного віднесення параметра до двох з існуючих класів.
- найближчих сусідів” приводить до знаходження двох класів з
найбільшою частотою попадання в групу з точністю 98%. Цей результат не використовується
для точного віднесення параметра до двох з існуючих класів.
Другий етап використовує 10 різних нейронних мереж для 10
різних парних класифікацій. Кожна нейронна мережа може використовувати зразки
тільки з двох відповідних класів у початковій вибірці. [2,3]
Метод класифікації „Відхилення
вибору” Точність класифікації може бути збільшена при
застосуванні методу відхилення вибору. Це є метод побудований на методі „![]() -найближчих сусідів” Спочатку
використовується (
-найближчих сусідів” Спочатку
використовується (![]() ) класифікація для відхилення завідомо невірних (викривлених)
даних, а потім - двоетапний класифікатор - безпосередньо для процесу
класифікації. Якщо кількість зразків тестової моделі менше, ніж у еталонної
моделі класу, тобто
) класифікація для відхилення завідомо невірних (викривлених)
даних, а потім - двоетапний класифікатор - безпосередньо для процесу
класифікації. Якщо кількість зразків тестової моделі менше, ніж у еталонної
моделі класу, тобто ![]() , система відхиляє тестову модель і не намагається її
класифікувати. Цей принцип використовується для відсіювання неякісних даних, за
якими не можна прийняти точного рішення заздалегідь, на початкових етапах
обробки[2,3].
, система відхиляє тестову модель і не намагається її
класифікувати. Цей принцип використовується для відсіювання неякісних даних, за
якими не можна прийняти точного рішення заздалегідь, на початкових етапах
обробки[2,3].
Висновок Отже, розглянувши та проаналізувавши деякі методи класифікації потоку вихідних
біометричних ознак за співвідношенням показників швидкодії роботи системи та її
точності і надійності, можна зробити висновок, що метод „Відхилення вибору” є
найоптимальнішим і дозволяє істотно підвищити точність системи. Його
особливість – багаторівневість: він є гібридом двох однорівневих методів
класифікації („![]() -найближчих сусідів” і „Нейронна мережа”) і, фактично, - трирівневим. Ця властивість методу дає
можливість зберегти достатньо високу швидкодію системи шляхом зменшення обсягу
вибірки на початковому етапі опрацювання інформації.
-найближчих сусідів” і „Нейронна мережа”) і, фактично, - трирівневим. Ця властивість методу дає
можливість зберегти достатньо високу швидкодію системи шляхом зменшення обсягу
вибірки на початковому етапі опрацювання інформації.
Література:
1. Інтернет – документ: http://masters.donntu.edu.ua/2010/fknt/kryvoukhov/library/article2.pdf
2. К. В. Воронцов, Лекции по метрическим алгоритмам классификации
3. Інтернет – ресурс: http://www.basegroup.ru/library/analysis/regression/knn/
4. Інтернет – ресурс: http://www.speech-text.narod.ru/chap4_2_1.html
5. Нейроинформатика /
А.Н.Горбань, В.Л.Дунин-Барковский, А.Н.Кирдин и др. - Новосибирск: Наука. Сибирское предприятие РАН, 1998. - 296с..