Korzh R.A.
Krivoy Rog national
university, Ukraine
Critical overview
of automatic music transcription
Introduction
Sound information represents as
a collection of the sounding objects. Sounding objects of a specific musical
instrument form a part. A part,
played on a single musical instrument is called a melody. A collection of parts of different musical instruments
forms a score. A score of the music
pieces contains a full description of notes of all musical instruments, i.e. it
represents an object-oriented form of
the piece of music. The piece of music is also characterized by tempo and degrees of musical polyphony (a number of
simultaneously sounding objects within a specific piece of music), object polyphony (a number of
simultaneously sounding objects within a specific musical instrument) and instrumental polyphony (a number of
simultaneously sounding musical instruments within a specific piece of music)
[4].
A complete transcription would
require that the pitch, timing and instrument of all the sound events be
resolved. As this can be very hard or even theoretically impossible in some
cases, the goal is usually redefined as being either to notate as many of the
constituent sounds as possible (complete
transcription) or to transcribe only some well-defined part of the music
signal, for example the dominant melody or the most prominent drum sounds (partial transcription) [1].
The process of object musical identification breaks into the three
directions [1, 5]:
1.
multipitch estimation (note and chord identification);
2.
musical metre estimation (measure, beat and tatum identification);
3.
instrument identification (instrument timbre matching).
According to [1, 3, 5], it is
possible to create a complementary classification
of the pieces of music due to their object content (table 1). Figure 1 shows that
a greater percent of developments is aimed to be oriented at the musical class
such as "many notes – many instruments".
Table 1 – Object classification of musical
masterpieces
|
Instruments Notes |
One |
Many |
|
One |
very rarely |
exclusively rarely |
|
Many |
not often |
very often |
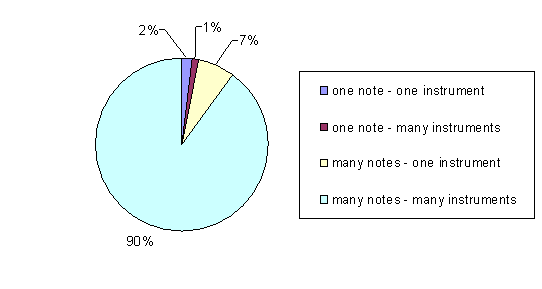
Figure 1 – Object classification of musical
masterpieces
Existing methods overview
One of the most inefficient
tries to realize the conversion process was related to Robert Maher [6]. Input audio signal has strictly limitations (only two separate voices are allowed and
others). Thus, the approach has the following disadvantages:
1.
the method
has strictly limitations and applies to an extremely narrow class of musical
masterpieces;
2.
the method
doesn't allow to determine chords and other musical objects;
3.
the noise and
the rest reverberations of input audio signal decrease the quality of
instrumental separation;
4.
separation of
musical parts and timbre identification of musical instruments are not allowed.
The systems of Emiya-Badeau-David [7] and Kashino-Murace [8] have a comparatively
better performance. They use time segment matching with the huge pattern
collection from the special databases. This approach is very robust and
imprecise, which proved in practice and has the following disadvantages:
1.
the method of
robust spectrum matching ignores small frequency components of the audio signal
which correspond to the fundamental frequencies;
2.
high tempo
analysis has a bad quality of recognition of sounding objects;
3.
A bigger
degree of musical polyphony determines a lot of mistakes in the recognition
procedures;
4.
there are
recognition errors in the bass and tremolo parts in the musical masterpieces.
Another widespread trend among
the researchers is using discrete Fourier transform algorithms. Striking
example is the project of Takuya
Fujishima showed in the figure 2 [9].
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
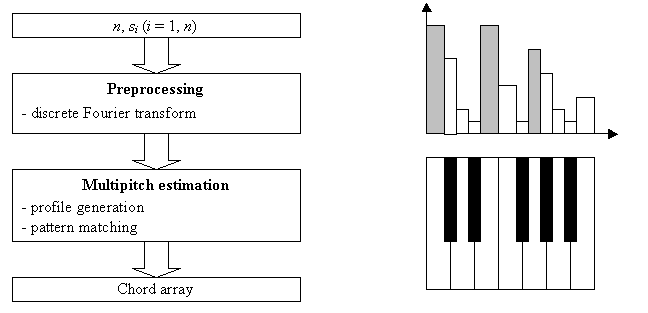

|
Figure 2 – Fragment of the algorithm of
Takuya Fujishima |
The current approach has the
following disadvantages:
1.
high quality
and performance are in case of ideal audio signals, otherwise, it is necessary
to implement more efficient mathematical base and recognition procedures;
2.
noise
component considerably decreases the chord recognition processes;
3.
there is a
small overlapping of the preceding and the starting notes at the octave edges;
4.
separation of
musical parts and timbre identification of musical instruments are not allowed.
Anssi Klapuri and Valentin Emiya convert signal spectrum
into a set to estimate fundamental frequencies. However, these approaches have important
disadvantages:
1.
beats and
tatum estimation has a bad accuracy in DFT-analysis of audio signals without
expression and amplitude accents;
2.
multipitch
estimation has low accuracy in cases of long notes and vibrato;
3.
a bigger
degree of musical polyphony determines a lot of mistakes in the recognition
procedures (due to partial overlapping in the frequency domain), and restricts
the application to real sound recognition tasks;
4.
there are
errors in the low and high frequency bands in polyphonic melody analysis.
Another widespread approach of
sound content identification of musical masterpieces is to use so-called blackboard systems [2]. Blackboard
systems usually consist of a central dataspace called the blackboard, a set of
so-called knowledge sources, and a
scheduler (fig. 3).
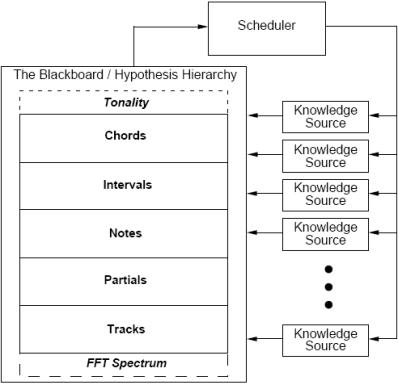
Figure 3 – The control structure of the
blackboard system
Such structured systems may be
found in the researches of Keith Martin
[3] and Bello-Sandler. It should be
noted that these systems use a comparatively small part of the whole control
structure, including a short list of knowledge sources as well (fig. 3). This
is connected with the knowledge source detailization (knowledge expert block
requires a complicated structure inside the central workspace). Another fact is
that these knowledge sources require semantic relations to cooperate with each
other. So, the task extremely grows and becomes more complicated.
Some developers apply linear
regression model and various teaching methods for the harmonic overlapping
separation.
Another effective approach is
the application of the wavelet transforms with neural network processing. This
method of identification is very similar to pattern recognition algorithms. Such
methods have been implemented by Livingston-Shepard and Alexander Fadeev [4]. Their quality and
performance are much bigger in comparison with the previous approaches, but, in
spite of this, there are some significant problems:
1.
the user
determines the wavelet scale coefficients, i.e. the adaptation to the specific
signal nature is missing;
2.
the basis
functions are Morlet wavelets, whose estimators don’t show an enough “matching”
with the sound waves of an analyzed signal (because they don’t completely match
to most timbre of the musical instruments), which results in bad accuracy in
the pattern recognition of musical instruments.
Conclusions
A brief introduction to
automatic music transcription described above shows that a great number of
scientists are involved and a huge number of experiments were made to reach
better results from year to year. A variety of developments proves its
necessity in many industrial and scientific projects. The recent systems have a
better performance and use the last mathematical achievements.
The overview of existing
automatic systems showed that it is necessary to run advanced research works in
the field of signal processing theory to develop a new approach which derives
all the previous advantages. And, the choice of the more efficient mathematical
model is also considered to increase the performance and accuracy in conversion
of music information.
References:
1.
Klapuri A.
Signal Processing Methods for Music Transcription / A. Klapuri, M. Davy. —
Springer, New York, 2006.
2.
Martin, K. D.
Automatic Transcription of Simple Polyphonic Music / K. D. Martin // Computer
Music Journal. — 2002. — No 1(7).
3.
Ellis, D.
Extracting Information from Music Audio / D. Ellis // LabROSA, Dept. of
Electrical Engineering Columbia University, NY, March 15, 2006.
4.
Фадеев,
А. С. Идентификация музыкальных объектов на основе непрерывного
вейвлет-преобразования / А. С. Фадеев // Диссертация. — Томский политехнический
университет. — 2008.
5.
Every, M.
Separation of musical sources and structure from single-channel polyphonic
recordings / M. Every // PhD thesis. — Department of Electronics. — University
of York. — 2006.
6.
Maher, R. C.
Development and evaluation of a method for the separation of musical duet
signals / R. C. Maher // Proc. IEEE Workshop on Applications of Signal
Processing to Audio and Acoustics, NY, Mohonk, October, 1989. — P. 1 — 3.
7.
Emiya, V.
Automatic transcription of piano music based on HMM tracking of
jointly-estimated pitches / V. Emiya, R. Badeau, B. David // Proc. Int. Conf.
Audio, Speech and Signal Processing (ICASSP). — 2009.
8.
Kashino, K.
Music recognition using note transition context / K. Kashino, H. Murase //
Proc. of the 1998 IEEE ICASSP. Seattle. 1998.
9.
Fujishima, T.
Realtime Chord Recognition of Musical Sound: a System Using Common Lisp Music /
T. Fujishima // Proc. of the International Computer Music Conference, Beijing:
International Computer Music Association, China, 1999. — P. 464 — 467.