Матвеев Дмитрий
Александрович
Некоторые предпосылки статистической обработки данных в исследованиях
агрессии
В исследованиях по педагогике, психологии, социологии часто используются методы математической статистики для обработки экспериментальных данных. В настоящее время есть как сторонники их использования, так и противники[1]. Данная работа ставит своей задачей проанализировать исходные предпосылки, которыми нужно руководствоваться при статистической обработке данных. Особенно это важно для исследований в области физической культуры, где исследователь сталкивается как с объективными данными (поднятый вес, частота сердечных сокращений, артериальное давление, жизненная емкость легких и др.), так и с субъективными (самооценка, данные педагогических наблюдений, интерпретация результатов тестов и т.д.).
В первую очередь, прежде чем приступить к статистической обработке экспериментальных данных представляется крайне необходимым получить общие сведения по теории вероятностей и математической статистике. Для получения таких сведений можно порекомендовать следующие издания: Б.В. Гнеденко «Курс теории вероятностей» Москва, 1965 год, В. Феллер «Теория Вероятностей» Москва, 1984 год, Фадеев «Экспериментальная обработка данных» Москва 2005 год. В книгах Анастази Урбина «Психологическое тестирование» Москва 2003 год, Э. Гидденс «Социология» Москва 2005 год есть разделы, посвященные использованию математики в психологии и социологии. Перечисленные издания отнюдь не исчерпывают полный список учебников и пособий, в которых излагаются общие сведения, необходимые для того, чтобы провести грамотную обработку экспериментальных данных.
Приступая к статистической обработке данных необходимо четко представлять, о чем идет речь. Все определения, дающие психологический, социологический, педагогический смысл должны, по меньшей мере, трактоваться одинаково. В противном случае получиться путаница из-за неоднозначности исходных понятий, что естественно затруднит понимание и обсуждение результатов, а возможно очень сильно впоследствии затормозит решение какой-нибудь очень важной задачи.
Получить какую-либо практически достоверную статистическую зависимость можно, если у нас число случаев достигает порядка 1015 и более, Даже если взять такую достоверную и известную статистическую закономерность как закон радиоактивного распада можно убедиться, что при очень малых количествах вещества, когда речь идет о тысячах или миллионах атомов, мы можем получить результаты, значительно отличающиеся от тех, что предсказывает этот закон. Такое количество случаев, конечно, не может быть набрано в педагогических, социологических и психологических экспериментах. Поэтому остается делать не однозначные выводы, а наиболее вероятные и наиболее практичные для решения научных или прикладных задач.
Перед тем как начать пользоваться методами матстатистики нужно помнить, что статистическую зависимость можно построить всегда, даже между двумя несвязанными никак величинами. Например, можно из двух разных ящиков вытаскивать наугад карточки с числами. Затем, исходя из значений чисел, нанести точки на координатную плоскость, аппроксимировать полученные точки полиномом N-ой степени, где N – количество точек на плоскости, получить коэффициент достоверности равным 1.00. однако, за всем этим не будет стоять никакого смысла. В действительности никакой зависимости не будет. Карточки с числами вытаскивались абсолютно случайно, и в следующий раз, зависимость будет совершенно другой. Таким образом, смотря только на числа, в том числе на высокие коэффициенты достоверности или корреляции, можно легко ошибиться и принять чистую случайность за существующий факт.
Рассмотрим пример, который приводит А. Гидденс в учебнике «Социология»[2].
В изученных Дюркгеймом обществах уровень
самоубийств постепенно повышается в период с января по примерно июнь или
июль. С этого момента и далее до конца
года он понижается. Можно предположить, что это указывает на то, что
температура и климатические изменения имеют причинностную связь со склонностью
индивидов к самоубийству. Возможно, по
мере повышения температуры люди становятся более импульсивными и
вспыльчивыми? Однако, причинностная
связь в этом случае, вероятно, вовсе не
имеет прямого отношения к температуре и климату. Это представление является
ложной корреляцией - ассоциацией,
которая кажется верной, но которая на деле вызвана неким другим фактором или
факторами.
Далее, становится понятно, что большинство людей ведут более активную социальную жизнь весной и летом, нежели зимой. Индивиды, которые одиноки и несчастливы, обычно испытывают обострение этих ощущений по мере того, как уровень активности других людей растет. Поэтому они, скорее всего, будут испытывать большую склонность к самоубийству весной или летом, нежели чем осенью или зимой, когда темп социальной деятельности замедляется.
Данный пример хорош также тем, что он наглядно показывает: даже абсолютно случайно полученная зависимость может быть объяснена третьим фактом или фактами. Если в исследовательской деятельности мы откинем ее как ненужный хлам, мы рискуем пройти мимо намека на разгадку, а может быть и мимо решения задачи. Нельзя слепо полагаться и верить всякой полученной зависимости, но и вообще отбрасывать ее - тоже опрометчиво.
Выборка, исходя из которой, строится статистическая зависимость, должна быть репрезентативна. Люди, входящие в состав этой выборки, должны относится к одной и той же однородной группе. Рассмотрим следующий пример. Для исследования влияния агрессивности на спортивный результат группа 2-3 разряда борьбы самбо, состоящая из студентов СПбГУ, заполнила опросник агрессивности, а затем в течение года фиксировались результаты, показанные группой на соревнованиях. Точно такой же эксперимент был проведен с группой КМС и 1 разряда, состоящей также из студентов СПбГУ. Далее искались корреляции в каждой группе по отдельности между уровнем агрессивности и показанными результатами на соревнованиях. В этом случае обе выборки репрезентативны, их состав однороден. Если же смешать две группы вместе, спортсмены из обеих групп будут принимать участие в одних и тех же соревнованиях, а затем провести статобработку имеющихся данных, то получится результат, который не будет характеризовать уровень спортивных достижений ни в одной группе, ни в другой. Выборка будет нерепрезентативна. Результат выступления на соревнованиях в первую очередь определяется спортивным мастерством. Поэтому для выявления влияния каких-либо психологических черт на спортивный результат нужна выборка, состоящая из спортсменов одной квалификации. Также отметим, что не всегда можно сравнивать показатели опросников, полученные на разных социальных группах например, проанализировав результаты тестирования по опроснику агрессивности Басса-Дарки, можно увидеть, что студенты иногда показывают более высокие результаты, чем лица отбывающие наказания за насильственные преступления. Разумеется, делать вывод о том, что кто-то из студентов агрессивнее заключенных неверно. Студенты и заключенные это разные социальные группы и сравнение результатов психологических тестов между ними должно быть строго оправданно. В данном случае сравнивать результаты тестирования просто нельзя.
В очень многих работах по психологии, педагогики, социологии для установления взаимосвязи между двумя величинами ищется коэффициент корреляции. Если он близок к единице или минус единице, то делается вывод имеющейся статистической зависимости между двумя величинами. Если он ближе к нулю, то, наоборот, считается, что величины между собой не имеют связи. Строго говоря, с точки зрения математики это не совсем так. Здесь нельзя не привести изумительный по своей простоте и красоте пример.
Рассчитаем коэффициент корреляции для точек с координатами (0;0), (1;1), (1;-1), (2;4), (-2;4), (3,9), (-3;9). Вычисления проведем с помощью программы Excel. В результате убедимся, что коэффициент корреляции будет равен нулю. Такой же результат будет получен при аппроксимации этих точек прямой линией (Рис. 1).
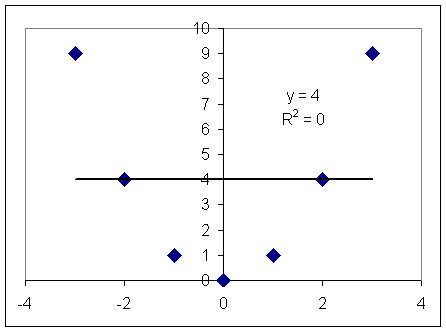
Рис. 1 Аппроксимация точек с помощью прямой линии.
У=4 – уравнения полученной аппроксимации, а R2=0 коэффициент достоверности этой аппроксимации. Однако из школьного курса математики нам известно, что эти точки лежат на параболе У=Х2. Действительно, попробуем с помощью Excel аппроксимировать данные точки с помощью полинома 2 степени (Рис 2).
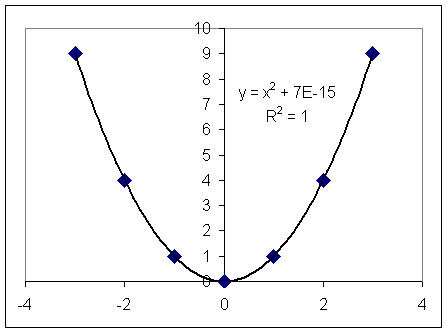
Рис.2 аппроксимация с помощью полинома 2-ой степени
Уравнение полученной аппроксимации У=Х2+7Е-15, т.е. практически как и предполагалось получилась парабола У=Х2. Погрешность приближения 7·10-15. Коэффициент достоверности R2=1.
В учебнике Б.В. Гнеденко «Курс теории вероятностей» М.,1965 год, стр. 179. рассматривается аналогичный пример и с помощью несложных математических преобразований доказывается, что действительно, если две величины линейно зависимы, то коэффициент корреляции равен единице или минус единице, обратное же неверно, как только, что было показано.
Проводя эксперимент и получая какие-либо точки на плоскости нужно помнить, что исследуемые величины могут быть связаны не только линейной зависимостью, но и какой-либо другой, или могут быть не связаны вообще.
Как бы банально и очевидно не звучало, но представляется крайне сомнительным придумывать какие-либо новые математические термины, определения или формулы, проводя статобработку полученных данных в ходе эксперимента.
Ссылки
1. Морозова С.В., Наследов А.Д. Проблема применения математических методов в психологических исследованиях: институализация статистического дискурса // Вестник СПбГУ Сер. 12, 2010 г, вып 4., С.180-184
2. Гидденс А. Социлогия М., 2005 г. 533 с.