Биркин Алексей Александрович
Гущин Юрий Геннадьевич
Московский институт
открытого образования
ПИСАТЕЛЬСКАЯ СЛАВА
И НАГРУЗКИ ДЕКОДИРОВАНИЯ ПЛОДОВ ВДОХНОВЕНИЯ
МАСТЕРОВ СЛОВА
Аннотация. Исследуется зависимость популярности
писателя (рейтинга) от физиологических
параметров
восприятия текстов его произведений, получаемых с помощью программ
диагностики
нагрузок кода речи.
Ключевые слова: популярность писателя
(рейтинг), физиологические параметры восприятия
художественных
текстов, программы диагностики нагрузок кода речи.
Популярность писателя (рейтинг) свидетельствует о достоинствах его
произведений, их актуальности и востребованности читательской аудиторией.
Персональный авторский рейтинг в числовых сравнимых величинах читателей или
рецензентов публикуется на массовых русскоязычных литературных сайтах «Лаборатория фантастики.ру», «Библиотека
фантастики», «Самиздат.ру» и «Проза.ру» [1].
Очевидно, чем больше читателей обращается к произведениям данного
автора, тем он успешнее и, наоборот.
Как выяснилось,
самыми
популярными писателями любителей электронных книг стали великие
русские классики – Толстой, Достоевский
и Чехов. А из современников наибольшей популярностью в России пользуются
Борис Акунин и Стивен Кинг [1].
Каковы же условия популярности произведений различных авторов? Не
вызывает сомнений, что первейшим таким условием является художественная ценность произведения,
которая основывается на осмыслении и понимании его текста. Но, к сожалению,
надежные и исчерпывающие формальные признаки, характеризующие данное условие,
пока получить не представляется возможным. Следовательно, в настоящее время нет
возможности подвергнуть данные признаки какому-то объективному
анализу. Вместе с этим, в самом начале восприятия речи в режиме реального
времени наша нервная система (НС) подготавливает к осмыслению, декодирует или
вычисляет коды букв и слов из поступающих через анализаторы зрительных и
звуковых сигналов. Чем больший ресурс она затрачивает на эту работу, тем меньше
сил ей, как ограниченной в возможностях вычислительной системе, остается на
понимание смысла текста, и наоборот. Экспериментально
доказано, что начальный досмысловой этап восприятия текста (декодирование) субъективно ощущается
человеком. Причем, чем больше текст отклоняется от эволюционно привычной модели
по своей структуре (встречаемости букв или длине слов в буквах), тем труднее он воспринимается и понимается. Эта
закономерность до настоящего времени не использовалась в качестве учитываемого
объективного прогностического критерия авторской популярности [2].
Следовательно, можно обоснованно предположить, что популярность
прозаического произведения зависит от физиологических параметров восприятия
авторского текста. Для подтверждения этой гипотезы возникает необходимость
анализа материалов наиболее массовых литературных сайтов с целью нахождения
зависимости популярности автора (количества читателей) от физиологических
параметров восприятия текста его произведения, получаемых с помощью программ
диагностики нагрузок кода речи.
В интересах достижения упомянутой цели в процессе исследований решались
следующие задачи: 1) за ограниченный период времени (3–4 часа), используя наиболее массовые
литературные сайты «Самиздат.ру» и «Проза.ру», сформировать репрезентативные
(статистически достаточные) случайные выборки прозаических произведений
популярных (более 30000 читателей) и менее признанных (менее 1000 читателей) авторов;
2) с помощью программ диагностики нагрузок кода речи оценить
физиологические характеристики восприятия текстов выборок; 3) провести
статистический анализ собранного материала.
Ранее, в контексте упомянутых гипотезы, целей и задач исследования были
опубликованы доказательные данные, свидетельствующие о целесообразности
подобного подхода к популярности текстов художественных произведений на примере
исследования сайтов «Лаборатория фантастики.ру», «Библиотека фантастики» [3].
Эти материалы иллюстрирует рисунок 1. На рисунке показаны средние значения
нагрузки первого этапа декодирования в выборках случайно взятых текстов
популярных (слева) и менее известных (справа) авторов, вычисленные с помощью
программы диагностики нагрузок кода речи версии 4.1–2006 г.
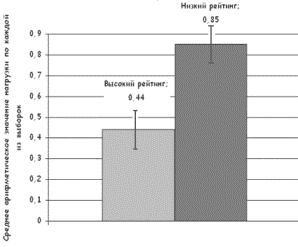
Рис. 1. Среднее арифметическое значение нагрузки первого этапа
декодирования при различной популярности произведений авторов-фантастов.
Как свидетельствуют представленные данные, в выборке текстов с низким
рейтингом средняя нагрузка в два раза выше по сравнению со средней нагрузкой
выборки текстов с высоким рейтингом (данные достоверны, р≤0,05,
соответственно 0,44+0,19 и 0,85+0,26, для расчетов использован Т-критерий
Стьюдента).
Итак, на основании обнаруженной
закономерности можно утверждать, что условием популярности авторского текста
являются его нагрузочные свойства. Эти свойства характеризуются показателем
средней динамической нагрузки 1-го этапа декодирования (буквообразования), не
превышающим 0,63 (0,44+0,19). Вычисляемый в используемой в данном случае
(4,1–2006 г.) версии программы показатель нагрузки, свойственной классу легких
текстов, не должен превышать 1,50.
Целью следующего исследования было подтверждение полученной
закономерности на основании более представительной выборки текстов различных по
жанру художественных произведений и с помощью более совершенной
пользовательской программы диагностики нагрузок кода речи версии 10.1–2009 г. В отличие от версии 4.1–2006 г. эта
программа позволяет вычислять параметры физиологии восприятия текста не только
по первому этапу декодирования – буквообразования, но и по второму этапу декодирования – словообразования.
Кроме того, на основании этих параметров она вычисляет интегральный показатель
данных показателей – физиологический индекс восприятия текста. Исходные материалы для
настоящего исследования на примере сайта «Самиздат.ру» представлены на рисунке
2.
Рис. 2. Исходные материалы для исследования: журнал «Самиздат.ру».
В отличие от версии 4.1–2006 г., программа версии 10.1–2009 г.
вычисляет параметры нагрузок декодирования в иных масштабных шкалах. Для
статистической обработки полученных c помощью этой программы результатов было использовано офисное программное
обеспечение «Excel.2007», а также
специальная программа для расчета достоверности различий долей. Для этого
строго по показаниям использовался U-критерий Фишера с применением φ (фи)
функции Фишера с поправками по Йетесу и Ван дер Вардену.
Данные статистической обработки полученных материалов по сайту
«Самиздат.ру» на примере физиологического индекса восприятия текста приведены в таблице 1, где: N – общее
количество наблюдений в группе, f – частотность или количество наблюдений в
группе с изучаемым признаком, Р% – доля наблюдений в группе с изучаемым
признаком, +m(p) % – стандартная
ошибка доли, критерий Фишера – вычисленное значение U-критерия Фишера, р<= – вероятность
ошибки или нулевой гипотезы. Принятым в биологических исследованиях критическим
(достоверным, значимым, доказательным) значением U - критерия Фишера является
величина, равная или большая 1,960. Это соответствует вероятности ошибки 5%
(0,05) и менее. Большее значение критерия соответствует меньшему значению
ошибки. В результате обработки параметров текстов с сайта «Самиздат.ру»
получены следующие результаты (таблица 1.).
Таблица 1
Физиологический индекс восприятия в группах текстов
произведений популярных и менее именитых авторов, опубликованных на сайте
«Самиздат.ру»
|
Тексты |
Популярные авторы, 82413-299519
читателей, N=40 |
Менее популярные авторы, 992-999 читателей, N=40 |
U-критерий Фишера |
p≤ |
||||
|
f |
P% |
±m(p)% |
f |
P% |
±m(p)% |
|||
|
«Легкие» тексты Индекс <= 108 |
38 |
93,8 |
3,8 |
27 |
67,5 |
7,4 |
3,166 |
0,01 (1%) |
|
«Тяжелые» тексты Индекс > 108 |
2 |
6,3 |
3,8 |
13 |
32,5 |
7,4 |
3,166 |
0,01 (1%) |
Как свидетельствуют приведенные данные при неограниченном количестве
подобных наблюдений (с достоверной степенью вероятности или с вероятностью
ошибки в 1 и менее процент), получаем неизбежно повторяющийся закономерный
результат. Исследования показывают, что
доля (%) более легких текстов (с индексом восприятия менее 108), превышает
таковую у авторов с громкими именами в сравнении с менее прославленными
писателями в 1,4 раза (соответственно
93,8+3,8% и 67,5+7,4%). Доля тяжелых текстов (с индексом
восприятия более 108) в 5,2 раза меньше у знаменитых писателей, нежели чем у
менее известных авторов (соответственно
6,3+3,8% и 32,5+7,4%). В
процессе дальнейших исследований при более жестких условиях статистической
обработки аналогичные закономерности нами были получены и на основании
исследования параметров 115 случайно отобранных текстов с сайта «Проза.ру».
Значит, популярность прозаического художественного произведения в
значительной степени зависит от физиологических параметров восприятия
авторского текста. Величина интегрального индекса восприятия текста
произведения меньшая, чем 108, увеличивает шансы на успех литератора в 1,4 раза. Недопущение индекса
декодирования за текст более, чем в 108 баллов, снижает риск попадания
сочинителя в число менее звездных в 5,2 раза.
Программные технологии кода речи, моделирующие работу НС в период
восприятия текста, позволяют не только прогнозировать популярность
художественных произведений, но и модифицировать их в интересах успешности
автора. Облегчение текстов по физиологическим параметрам способствует
сохранению ресурсов нервной системы читателя. Это актуально для развития
здоровьесберегающих технологий в образовании. В этой связи с точки
зрения полученных данных представляет значительный интерес оценка
психофизиологических парметров статей школьных учебников.
На рисунке 3 показаны в режиме реального времени чтения текстовые
нагрузки 1-го этапа декодирования учебников по истории для 9 и 11 классов в
сравнении с возможностями восприятия взрослого человека (до 1,5 баллов) и с параметрами
текстов популярных творцов (до 0,44 балла). По этическим соображениям имена
авторов учебников не указываются.
Ниже в таблице 2 приведены данные обработки и по другим учебникам,
тексты которых оказались доступными из сети Интернет. Все они рекомендованы
Министерством образования и науки РФ.
Данными о допустимых текстовых нагрузках для детей различных возрастных
групп мы пока не располагаем. Но даже для взрослого человека эти нагрузки
огромные, а что говорить о ребенке? Ведь этот материал ретранслируется в
методических разработках и устной речи учителя на уроке, не говоря уже о том,
что с этими текстами работают дети.
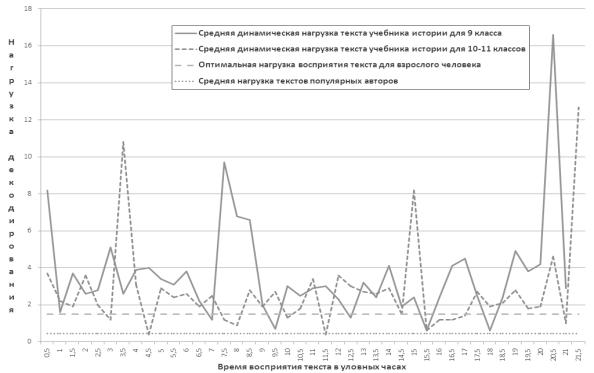
Рис. 3. Нагрузки кода
речи учебников по истории для 9 и 11 классов.
А теперь попробуем ответить на вопрос: "Почему же значительная
часть школьников учебники не читает, а воспринимает материал "на
слух" на уроке или в процессе общения между собой?" Полагаем, ответ
ясен...
Попробуем ответить и на второй вопрос:
"Что делать?" На рисунке
4 показаны данные по учебнику литературы. Этот учебник написал известный автор, обладающий не только глубокими знаниями
в области филологии, но и языковой интуицией. Как видно из графика, текст этого
учебника на порядки легче предыдущих и является легким в восприятии.
И опять вопрос: "А можно ли все тексты школьных учебников привести
к подобным идеальным параметрам, не изменяя их содержания?" Принципиально
– да. Русский язык настолько богат, что заменяя некоторые слова синонимами,
любой текст можно привести к параметрам физиологической нормы без искажения его
смысла. Однако неизвестно каким количеством специалистов подобного высокого
уровня мы располагаем. Видимо объем необходимой работы будет большим, чем общие возможности подобных специалистов,
даже если они объединятся, и будут решать только эту проблему. И сколько
времени для этого потребуется?
Таблица 2
Нагрузки декодирования случайно отобранных из сети Интернет
текстов
школьных учебников
|
Название учебника |
Средняя нагрузка
декодирования текста учебника |
Превышение нагрузки
текста учебника над параметрами легкого (для взрослого человека) текста (1,5
%) |
Превышение нагрузки
текста учебника над параметрами текста популярного автора (0,44 %) |
|
Учебник по биологии для 10-11 кл. |
4,6 |
В 3,1 раза |
В 10,5 раза |
|
Учебник по физической географии для 10-11 кл. |
5,9 |
В 3,9 раза |
В 13,4 раза |
|
Учебник по истории для 9 кл. |
3,6 |
В 2,4 раза |
В 8,9 раза |
|
Учебник по истории для 10-11 кл. |
2,7 |
В 1,8 раза |
В 6,1 раза |
|
Учебное пособие по истории для 1--11 кл. |
5,8 |
В 3,9 раза |
В 13,2 раза |
По нашему глубокому убеждению, выход из создавшейся ситуации может быть
только один – обучение специалистов соответствующих центров и учителей школ
использованию программ кода речи. Однако, как показывает более чем пятилетний
опыт преподавания психофизиологии кода речи в Московском институте открытого
образования, низкая мотивация и уровень компьютерной грамотности практикующих
педагогов позволяет научить их лишь основам использования простейших программ,
которые определяют нагрузки восприятия, а, следовательно, и отбора учебных
текстов. До реальных процедур облегчения (модификации) текстов дело, как
правило, за редким исключением, не доходит, несмотря на то, что все программы
кода речи в использовании значительно проще, чем распространенный текстовый
редактор "Word".
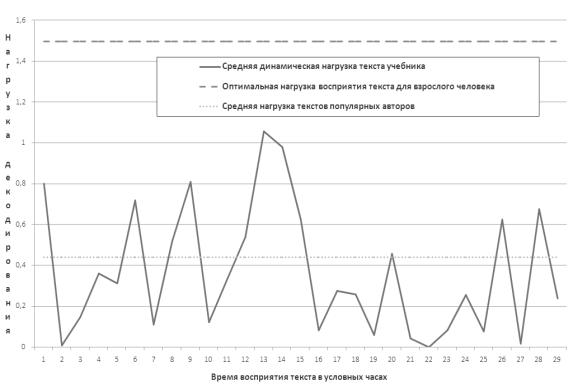
Рис. 4. Нагрузки кода
речи учебного пособия по литературе для 10 класса.
Список использованной
литературы
1.Сайт «Библиотека фантастики»/ http://www.fant-lib.ru/ Сайт «Лаборатория фантастики»/ http://www.fantlab.ru/ Сайт «Проза.ру»/ http://www.proza.ru/ Сайт «Самиздат.ру»/ http://zhurnal.lib.ru/http://readrate.com/rus/news/10-samykh-chitaemykh-elektronnykh-avtorov
2. Биркин А.А. Код речи. –Гиппократ:
СПб, 2007. – 407 с.; Биркин А.А. Природа речи. – Ликбез: М., 2009. – 384 с.
3.
Там же. С. 215–221.