Современные
информационные технологии/Вычислительная техника и программирование
Мясищев А.А.
Хмельницкий национальный университет, Украина
Анализ
скоростей передачи данных между процессами в параллельных вычислительных
системах
При решении
ряда прикладных задач, описываемых дифференциальными уравнениями в частных
производных, возникает необходимость в перемножении квадратных матриц большого
порядка и решении систем линейных уравнений. В частности при решении задач
теории упругости, пластичности, которые сводятся к решению систем
дифференциальных уравнений в напряжениях и скоростях, используется метод
конечных элементов. В свою очередь данный метод сводится к построению матриц
жесткости, перемножению матриц и решению систем линейных уравнений, содержащей тысячи
и даже десятки тысяч неизвестных. При решении пластических задач решение таких
задач приходится выполнять сотни и тысячи раз для выявления конечной
конфигурации деформируемого материала. Это требует вычислительных систем
высокой производительности. В настоящее время широкое распространение получили
компьютеры с многоядерными процессорами. Например, двуядерные и четырехядерные
процессоры фирмы Intel (E2160, Q6600)
и AMD(Athlon 64x2 4000+). Причем
прогрессирование технологии производства процессоров в настоящее время идет о
пути увеличения числа ядер. И как отмечают производители, обычный персональный
компьютер с одним из таких процессоров превращается в параллельную
вычислительную систему с общей памятью (SMP-система). Проблема заключается в
том, чтобы распараллелить, например задачи решения систем линейных уравнений и
перемножения матриц так, чтобы получить максимальную загрузку многоядерного
процессора и выигрыш в производительности примерно соответствующий числу ядер.
Параллельно многоядерным системам также развиваются и кластерные системы с
распределенной памятью, соединенные между собой быстродействующими
коммуникациями. При параллельном решении задач на этих системах неизбежно
решается задача о пересылке данных между процессами, и чем выше скорость пересылок,
тем эффективнее распараллеливание.
Основой для параллельного выполнения программ для параллельных
вычислительных систем является модель передачи сообщений. В этой модели
параллельная программа представляет собой систему процессов, которые функционируют
независимо друг от друга. Взаимодействие процессов через среду передачи данных
(компьютерную сеть, разделяемую память) требует дополнительных затрат времени.
Обмены между процессорами в параллельной системе происходят путем передачи
через коммуникационную среду численной или иной информации. Существует две
основные характеристики коммуникационных сред: латентность – время начальной задержки при посылке сообщений и
пропускная способность коммуникационной системы, определяющая скорость передачи
информации между процессорами. При решении реальных параллельных задач важны
реальные, а не пиковые характеристики, которые достигаются, например, при решении задач методом MPI. Так, например, после
вызова функции посылки сообщения оно последовательно пройдет через набор слоев,
определяемых особенностями реализации ПО и аппаратуры, прежде чем сообщение
покинет процессор. Это порождает
латентность. Следовательно, максимальная скорость передачи через
коммуникационную среду достигается на больших сообщениях, когда доля времени латентности в процессе передачи полного набора данных
мала.
Рассмотрим количественные
характеристики межпроцессорного обмена.
Пропускная способность среды передачи представляет собой количество информации, передаваемой
между узлами в единицу времени (байт в секунду). Латентностью называется время, затрачиваемое программным
обеспечением и устройствами, по которым осуществляется обмен информацией, на
подготовку к передаче сообщений по данному каналу. Латентность (задержка) —
один из основных показателей эффективности коммуникационной инфраструктуры
параллельной системы (кластера). Эта задержка включает в себя программный
компонент (задержка, определяемая стеком протоколов TCP/IP, а также возможные
накладные расходы, связанные с копированием передаваемых данных из буферов
пользователя в буферы ядра операционной системы) и аппаратный компонент.
В последний, кроме задержек на портах коммутаторов, входят и задержки на
сетевых платах. Латентность измеряется как время,
необходимое на передачу сигнала или сообщения нулевой длины. При измерении латентности для снижения влияния
погрешности и низкого разрешения системного таймера важно повторить операцию
посылки сигнала и получения ответа большое число раз.
В системах с
общей памятью также можно ввести понятие латентности, как времени передачи
данных нулевой длины между программными компонентами единой параллельной
программы, расположенными на разных ядрах процессора.
При
проведении опытных исследований рассматривались компьютерные системы на базе
процессоров Intel: Q6600, E2160;
AMD Athlon 64x2
4000+. Для определения скорости пересылок два компьютера с процессором Q6600
объединялись через коммутатор DES-3326SR фирмы DLink с целью обеспечения
сетевого взаимодействия по сети Ethernet со скоростями 100Мбит/с и 1000Мбит/с . В
другом случае компьютеры с процессорами Q6600, E2160 и Athlon 64x2
4000+ работали в автономном режиме для определения скорости пересылок между
ядрами процессора. В обоих случаях определялось время латентности и скорости
пересылок для массивов двойной точности разной длины. Скорости пересылок (но не
латентность) сравнивались со скоростями передачи данных при копировании
массивов в оперативной памяти для одного процесса, который выполнялся в одном
ядре. Затем рассчитывались отношения времен пересылок между процессами по
технологии MPI и пересылками
внутри памяти. Опыты проводились с использованием операционной системы PelicanHRC GNU/Linux v.1.7.2., которая запускается
как “live CD”. При ее установке на узловые
компьютеры организуется высокопроизводительная параллельная кластерная система
с использованием MPI. Ниже представлена программа по
определению времени латентности и скорости передачи сообщений между
процессорами для двунаправленных пересылок, которая написана на языке FORTRAN:
program latentnost
include
'mpif.h'
integer ierr, rank, size,
i, n, lmax, NMAX, NTIMES
parameter (NMAX = 1000000,
NTIMES = 100)
double precision
time_start, time_stop,time, bandwidth
real*8
a(NMAX),b(NMAX),t(1000),t1(1000)
integer
status(MPI_STATUS_SIZE)
call MPI_INIT(ierr)
call
MPI_COMM_SIZE(MPI_COMM_WORLD, size, ierr)
call
MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
c Задание
исходных данных
n =0
ii=1
do ia=1,NMAX
a(ia)=ia*1.0d0
end do
c Начало цикла
расчета
do while (n.le.NMAX)
c NTIMES пересылок для
осреднения результата
if(rank
.eq. 0) then
time_start = MPI_WTIME(ierr)
do i = 1, NTIMES
call MPI_SEND(a, n,
MPI_DOUBLE_PRECISION, 1, 1,
& MPI_COMM_WORLD, ierr)
call MPI_RECV(a, n,
MPI_DOUBLE_PRECISION, 1, 1,
& MPI_COMM_WORLD, status, ierr)
time =
(MPI_WTIME(ierr)-time_start)/2/NTIMES
bandwidth = (8*n*1 .d0/(2**20))/time
end do
end if
if(rank.eq.1) then
do i = 1, NTIMES
call MPI_RECV(b, n,
MPI_DOUBLE_PRECISION, 0, 1,
&MPI_COMM_WORLD, status,
ierr)
call MPI_SEND(b, n,
MPI_DOUBLE_PRECISION, 0, 1,
& MPI_COMM_WORLD, ierr)
end do
end if
c Конец NTIMES пересылок для осреднения
результата
c Расчет времени двойной пересылки и скорости
в МБайт/с
c
if(rank .eq. 0) then
if(n .eq. 0) then
c Если
длина пересылаемых данных равна нулю, то это латентность
print *, 'latency = ',
time, ' seconds'
c В другом случае
распечатывается длина сообщения и скорость
else
print *, 8*n, ' bytes,
bandwidth =', bandwidth,
& ' Mb/s',' time=', time,
' n=',n
t(ii)=time
ii=ii+1
end if
end if
c
if (n.eq.0) then
n=1
else
n=2*n
end if
end do
c Конец цикла расчета
n=1
c Расчет для одного процесса в оперативной
памяти
if(rank
.eq. 0) then
ii=1
print *, 'Memory'
do while (n.le.NMAX)
time_start =
MPI_WTIME(ierr)
do i=1,NTIMES
do j=1,n
b(j)=a(j)
end do
do j=1,n
a(j)=b(j)
end do
end do
time_stop=MPI_WTIME(ierr)
time=(time_stop-time_start)/2/NTIMES
bandwidth = (8*n*1
.d0/(2**20))/time
print *, 8*n, ' bytes,
bandwidth =', bandwidth,
& ' Mb/s',' time=',
time, ' n=',n
t1(ii)=time
ii=ii+1
n=2*n
end do
do m=1,ii-1
c
Определение отношения времен пересылки между процессами и памятью
tim=t(m)/t1(m)
print *,'proc/mem=',tim
end do
end if
call MPI_FINALIZE(ierr)
end
При составлении программы использовался интерфейс обмена
сообщениями (Message Passing Interface, MPI). Ниже представлены основные
функции, которые задействованы в программе:
MPI_INIT
(IERROR)
Функция завершения MPI
программ MPI_Finalize
MPI_FINALIZE
(IERROR)
Функция закрывает все MPI-процессы
и ликвидирует все области связи.
Параметр IERROR является выходным и возвращает код
ошибки.
Функция определения
числа процессов в области связи MPI_COMM_SIZE:
MPI_COMM_SIZE (MPI_COMM_WORLD, SIZE, IERROR)
MPI_COMM_WORLD
- коммуникатор;
SIZE
- число процессов в области связи коммуникатора MPI_COMM_WORLD.
Функция определения
номера процесса MPI_COMM_RANK:
MPI_COMM_RANK (MPI_COMM_WORLD, RANK, IERROR)
MPI_COMM_WORLD
- коммуникатор;
RANK
- номер процесса, вызвавшего функцию.
Номера процессов лежат в
диапазоне 0..SIZE-1 (значение SIZE может быть определено с
помощью предыдущей функции).
Функция передачи
сообщения MPI_SEND:
MPI_SEND (BUF, COUNT, DATATYPE, DEST, TAG, MPI_COMM_WORLD, IERROR)
BUF - адрес начала расположения пересылаемых данных
(массив или скалярная величина);
COUNT
- число пересылаемых элементов (для скалярной величины COUNT=1);
DATATYPE - тип посылаемых элементов (MPI_REAL,
MPI_DOUBLE_PRECISION, MPI_INTEGER);
DEST - номер
процесса-получателя в группе, связанной с коммуникатором MPI_COMM_WORLD;
TAG
- идентификатор сообщения;
MPI_COMM_WORLD
- коммуникатор области связи.
Функция
приема
сообщения - MPI_RECV
MPI_RECV (BUF, COUNT, DATATYPE, SOURCE, TAG, MPI_COMM_WORLD,
STATUS,
IERROR)
BUF
- адрес начала расположения принимаемого сообщения;
COUNT
- максимальное число принимаемых элементов;
DATATYPE
- тип элементов принимаемого сообщения;
SOURCE
- номер процесса-отправителя;
TAG
- идентификатор сообщения;
MPI_COMM_WORLD
- коммуникатор области связи;
STATUS (MPI_STATUS_SIZE)
- массив атрибутов приходящего сообщения. В Фортране параметр STATUS является целочисленным массивом размера MPI_STATUS_SIZE. Константы MPI_SOURCE, MPI_TAG, MPI_ERROR - являются
индексами по данному массиву для доступа к значениям соответствующих полей:
STATUS (MPI_SOURCE) - номер
процесса-отправителя сообщения;
STATUS (MPI_TAG) - идентификатор сообщения;
STATUS (MPI_ERROR) – код ошибки.
Функция времени – таймер
MPI_WTIME()
Функция
возвращает астрономическое время в секундах, прошедшее с некоторого момента в
прошлом (точки отсчета). Гарантируется, что эта точка отсчета не будет изменена
в течение жизни процесса. Для хронометража участка программы вызов функции
делается в начале и конце участка и определяется разница между показаниями
таймера.
Для передачи данных между компьютерами с процессорами Q6600
по сети Ethernet файл /home/user/tmp/bhosts
имел следующий вид:
10.11.12.1
cpu=1
10.11.12.2
cpu=1
Для пересылок между
ядрами процессоров Q6600, E2160, Athlon
64x2 4000+
10.11.12.1 cpu=2
Для перехода к разным
моделям параллельных систем использовалась команда
lamboot /home/user/tmp/bhosts
После
этого
выполнялась
компиляция
mpif77 -O3 latentnost.f -o latentnost
и запуск на выполнение
mpirum -C latentnost
Здесь
latentnost.f - имя программы,
-O3 - ключ оптимизации транслятора FORTRAN.
Позволяет отследить эффект кэш памяти 1-го уровня
C - запуск при использовании всех узлов
кластера (ядер процессора)
Ниже
представлены результаты исследований.
В таблице 1 показаны
значения латентности для разных параллельных систем.
Таблица 1 - латентность
|
Система |
Латентность
в микросекундах |
|
Q6600 – Fast Ethernet |
47.8 |
|
Q6600 – Gigabit Ethernet |
31.6 |
|
Q6600 – Memory (пересылка между
ядрами) |
3.9 |
|
E2160 – Memory |
6.7 |
|
Athlon 64x2 4000+ - Memory |
5.5 |
Согласно таблице
латентность для сети Ethernet в 10-15 раз выше
латентности по сравнению с пересылками между ядрами процессоров через
разделяемую память.
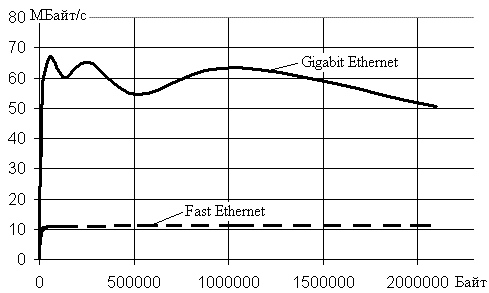
Рис.1.
На рис.1 представлен график зависимостей скорости передачи
данных для межпроцессорных коммуникаций, организованных сетями Fast
Ethernet и Gigabit Ethernet в зависимости от
размера передаваемых данных. Использовалась система на базе процессоров Q6600.
Результаты работы программы показывают, что при длинах пересылаемых данных
больше 16000 байт скорость передачи стабилизируется значениями ~10Мбайт/с для Fast
Ethernet и ~60Мбайт/с для Gigabit Ethernet.
На рис.2 представлен график зависимостей скоростей передачи
межпроцессорных данных для Fast
Ethernet и Gigabit Ethernet имеющих размеры до 2000
байт. Использовалась система на базе процессоров Q6600. Видно, что для
размеров данных до ~200 байт скорости
передачи для Fast Ethernet и Gigabit Ethernet примерно одинаковы, но
например, для значений в1000 байт и выше скорости отличаются в два и больше
число раз.
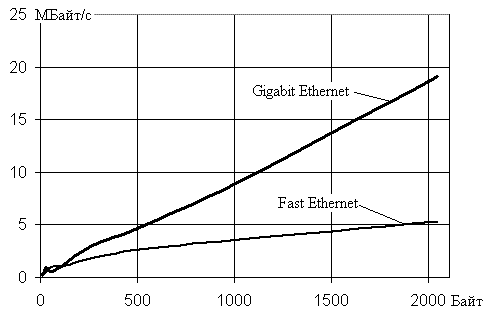
Рис.2.
На рис.3 представлен график зависимостей скоростей передачи
межпроцессорных данных для многоядерной
системы на базе процессора Q6600 в зависимости от
размера данных. Кривые 1 и 2 соответствуют пересылкам между разными массивами
данных в пределах одного ядра процессора. Однако 1-я кривая построена по
результатам решения при установке оптимизационного ключа –O3 при компиляции. Кривая 2 построена по
результатам решения без ключа оптимизации при компиляции. Кривая 3
соответствует зависимости скорости пересылки данных между ядрами процессора от величины
пересылаемых данных, полученная с использованием библиотек MPI.
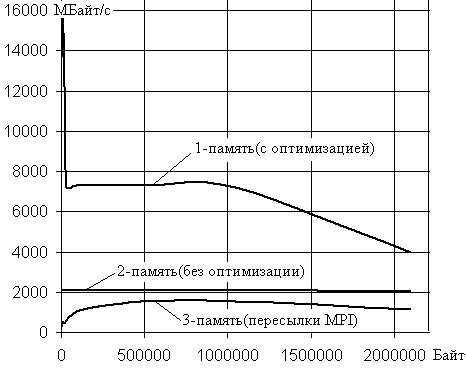
Рис.3.
Видно, что чем больше
объем пересылаемых данных, тем ближе скорости пересылок приближаются друг к
другу. При сравнении кривых 1 и 2 видно влияние кэш памяти 1-го и 2-го уровней
на скорость пересылки. Например, кэш-память 2-го уровня отчетливо
прослеживается на размере пересылаемых данных длиной до 1000000 байт, после
чего ее влияние уменьшается в пределе до 4000000 байт (график представлен
несколько урезанным).
На рис.4 представлен график зависимостей скоростей передачи
межпроцессорных данных для многоядерной
системы на базе процессора Q6600 для малых размеров
передаваемых сообщений (до 64000 байт). Как и в предыдущем случае, кривая 1
построена с ключом оптимизации –O3 и отображает интервал
влияния кэш памяти 1-го уровня. Видно, что скорость пересылок в области размера
данных 200-30000 байт существенно превышает скорости для двух других случаев.
Однако если кривые 1 и 2 при длине данных начиная с 8 байт сразу соответствуют скоростям
передачи 4000 и 2000 Мбайт/с, то 3-я
кривая начинается со значений ~1 Мбайт/с постепенно увеличиваясь до 300Мбайт/с
для размера пересылаемых данных 4000
байт. Это свидетельствует о том, что межъядерная пересылка данных внутри
оперативной памяти очень неэффективна для размеров, соизмеримых с размерами
переменных. Фактически здесь имеет место аналогичная ситуация, как и для
пересылок данных малых размеров в условиях Gigabit Ethernet.
Поэтому создание параллельных алгоритмов, связанных с пересылкой значений
переменных (не массивов) не эффективно даже для многоядерных систем при работе
с общей памятью.
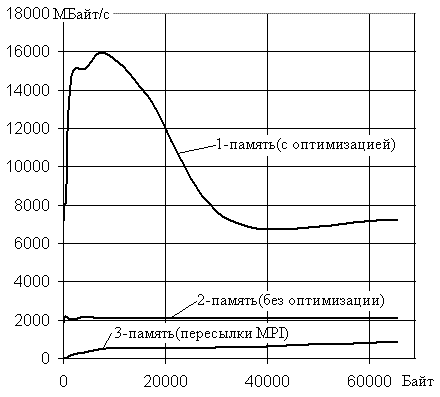
Рис.4.
На рис.5 представлен график зависимостей скоростей передачи
данных при их пересылке в оперативной памяти для одного процесса между
массивами для трех разных систем с процессорами: Q6600 (1-я кривая), Athlon 64x2
4000+ (2-я кривая), E2160(3-кривая). Все кривые построены по
результатам решения при установке оптимизационного ключа –O3 при компиляции. Из графика видно, что
процессор Q6600 с памятью работает существенно быстрее, чем другие
процессоры, однако интервал действия кэш памяти 1-го уровня у процессора Athlon
больше примерно в два раза, чем у процессоров Intel, хотя она медленнее,
чем у Intel.
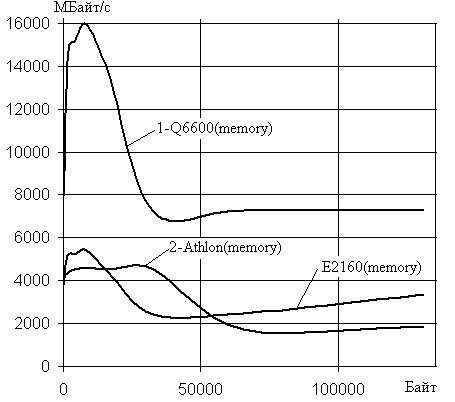
Рис.5.
На рис.6 представлен график зависимостей скоростей передачи
данных при их пересылке в разделяемой памяти для двух процессов между ядрами с
использованием MPI для трех систем с процессорами: Q6600 (1-я кривая), Athlon 64x2
4000+ (2-я кривая), E2160 (3-кривая).
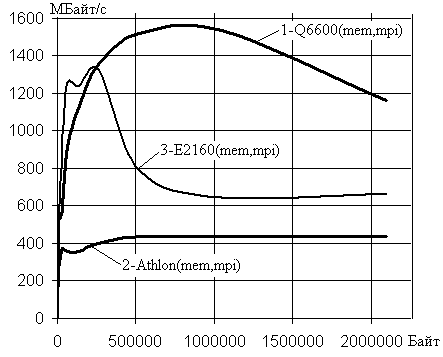
Рис.6.
Рассмотрим, как меняется отношение скоростей пересылок в
зависимости от длины данных между процессами для MPI и в пределах
оперативной памяти для одного процесса (в пределах ядра процессора) для систем
с процессором Q6600, когда пересылки по MPI проводятся через Fast
Ethernet, Gigabit Ethernet
и разделяемую память.
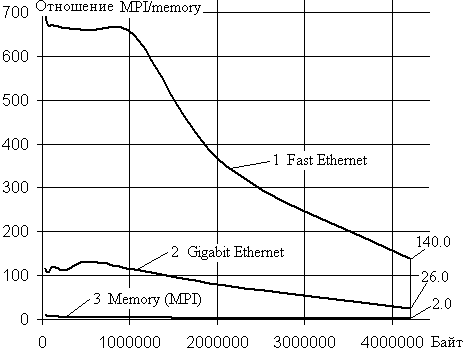
Рис.7.
На рис.7
представлен график зависимости изменения отношения скоростей для пересылки
данных размером до 4194304 байт. В конце кривых указаны минимальные значения
отношений. На рис.8 представлен аналогичный график зависимости изменения
отношения скоростей для пересылки данных, но размером до 1024 байт. Цифрами у
каждой кривой указаны минимальные значения отношения скоростей для этого
диапазона размера передаваемых данных. Расчеты выполнялись с ключом оптимизации
–O3. Интересно отметить, что скорость пересылки данных в оперативной памяти до 2000 раз выше даже
скорости пересылки в разделяемой памяти
с помощью MPI, не говоря уже при обмене данными через Fast
Ethernet и Gigabit Ethernet.
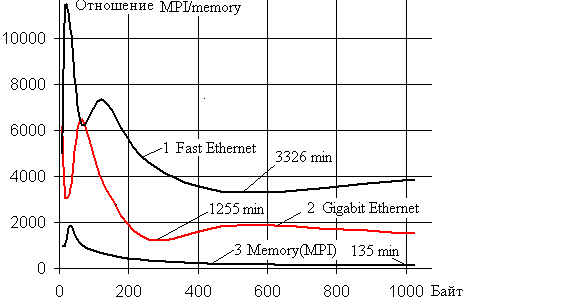
Рис.8.
На основании изложенного материала можно сделать следующие
выводы.
1. Латентность для Gigabit
Ethernet примерно в 1.5 раза меньше чем для Fast
Ethernet
2. Латентность для сети Gigabit
Ethernet примерно в 10 раз выше латентности по сравнению
с пересылками между ядрами процессоров через разделяемую память
3. Увеличение в 2 и более
раз скорости передачи данных для Gigabit Ethernet по сравнению с Fast Ethernet
между процессами наблюдается при размере передаваемых данных более 1000 байт.
4. В случае использования оптимизационного ключа
–O3 при компилировании программы скорость обмена внутри памяти
для одного процесса существенно возрастает за счет использования кэш памяти.
Особенно резко возрастает быстродействие при работе с кэш памятью 1-го уровня.
При пересылке данных между ядрами процессора через общую память, кэш память не
используется, поэтому для значений данных свыше 500000 байт скорости обмена
внутри памяти и скорости пересылок с помощью MPI через общую память
отличаются незначительно, если не использовать ключ оптимизации компилятора –O3.
5. При создании
параллельных программ даже для многоядерных процессоров, эффективность
распараллеливания наблюдается лишь в случае, если размер пересылаемых данных
превышает 40000 байт. В этом случае отношение времен пересылок уменьшается от 10
до 1,8 раз.
6. В обозримом будущем не
целесообразно создавать параллельные алгоритмы, связанные с межъядерными
пересылками данных, соизмеримых с размерами переменных, так как скорости
пересылок в тысячи раз меньше, чем для одноядерных систем с кэш памятью.
Литература.
1. Воеводин В.В., Воеводин Вл.В.
Параллельные вычисления. –СПб: БХВ – Петербург, 2004.-608 с.: ил.